Enterprise AI · Governed systems
AI that can be operated and reviewed.
We build RAG, agents, and copilots with the same controls expected of production services: identity, approval, evaluation harnesses, audit trails, observability, and SLOs.
The AI stack, treated like a system.
Every layer below has explicit operating controls: SLOs, observability, identity, audit, fallback behavior, and ownership.
RAG over enterprise data
Document ingestion, embedding pipelines, vector stores, hybrid search, and retrieval that respects the user's access boundaries.
- Identity-aware retrieval
- Ingestion pipelines
- Vector store + hybrid search
- Eval harnesses
Governed agents
Agents with bounded tool use, approval steps, and audit trails. We treat agents like services: SLOs, observability, runbooks.
- Bounded tool use
- Approval workflows
- Replayable traces
- Service-grade SLOs
Evaluation & guardrails
Eval harnesses that catch regression on real prompts, with judged rubrics, drift detection, and red-team baselines.
- LLM-as-judge eval
- Golden sets
- Regression dashboards
- Red-team baselines
Identity, approval, audit
Every prompt, retrieval, tool call, and write action carries an identity, an approval, and an audit record. Procurement-ready by default.
- End-to-end identity
- Approval gates
- Write-action audit
- Tenant boundaries
Model strategy
Model selection across Azure OpenAI, open weights, and domain-tuned options, with routing and fallback designed before production use.
- Azure OpenAI
- Open-weights via vLLM
- Domain fine-tuning
- Routing & fallback
Production observability
Prompt-level traces, cost attribution, latency budgets, drift detection, and review dashboards for production teams.
- Trace + cost per request
- Latency budgets
- Drift detection
- PII detection
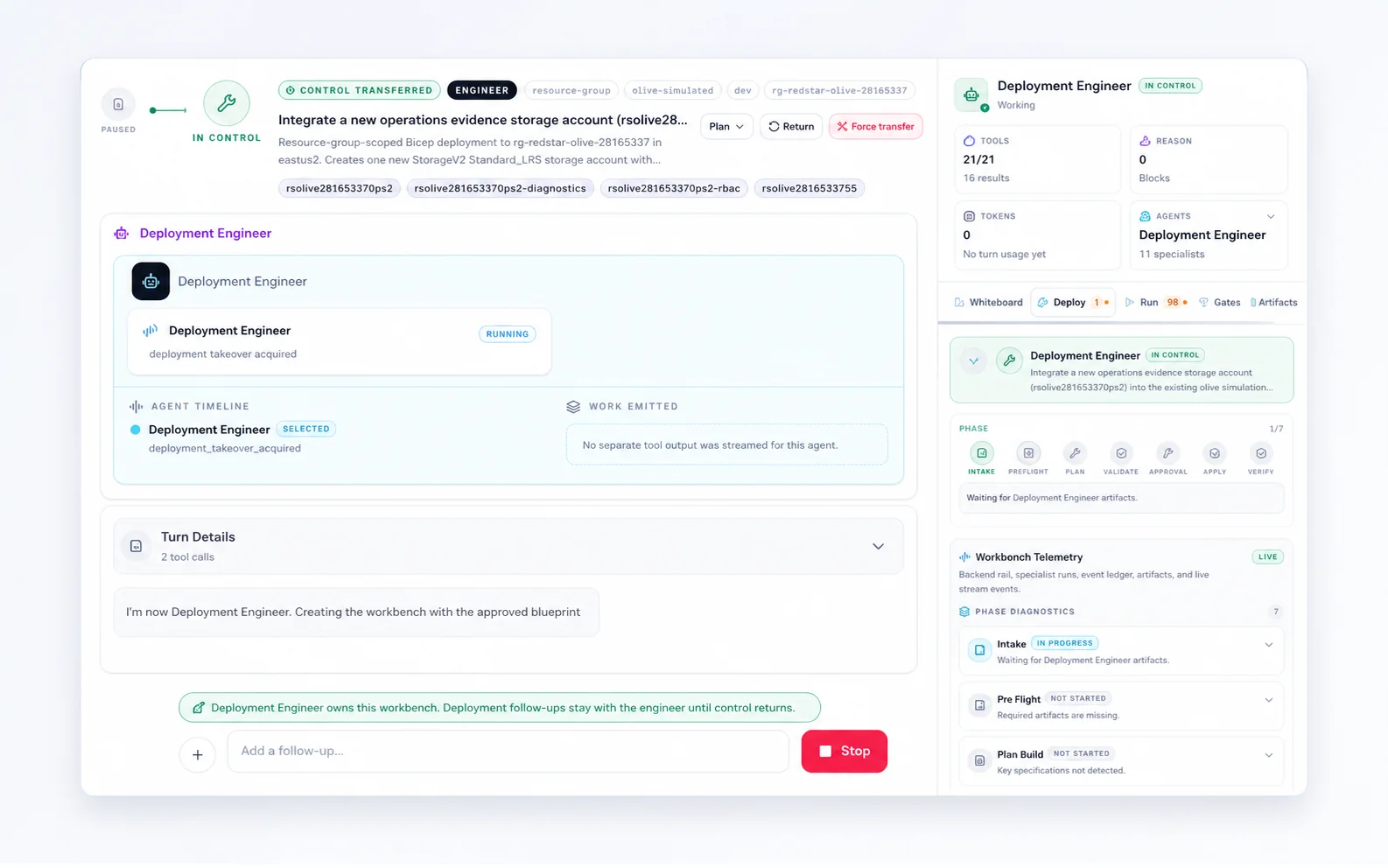
Operating model
Enterprise AI needs a workbench, not just a model endpoint.
A production AI feature has to show what it retrieved, which specialist owns the task, what phase the work is in, which actions need approval, and what evidence will be retained. That is the difference between a demo and a system a platform, security, or operations team can trust.
See the product pattern inside LineageFour rules for production AI.
Workflow first
We start with the workflow, success criteria, approval boundaries, and evidence requirements. Model selection follows the operating requirement.
Evaluation before production
AI features need a written evaluation plan, golden sets, regression checks, and reviewable measurements before production rollout.
Identity end-to-end
Retrieval and writes carry user identity. Approval gates and audit logs are mandatory for write-class operations.
Review-ready architecture
Data residency, model isolation, audit trails, tenant boundaries, and operational ownership are documented before production use.
Workflows, not chatbots.
Document-grounded knowledge agents
Retrieval-grounded answers over policy, contracts, runbooks — with citations and access controls that pass audit.
Investigation copilots
Atlas-style copilots for operations: surface signals, propose actions, but route writes through approval and audit.
Reporting & evidence agents
Agents that compose reports against structured + unstructured sources, with the data lineage attached.
Code & infra copilots
Internal copilots for IaC, code review, and policy compliance, connected to approved repositories and CI workflows.
AI work that can be inspected before it acts.
The important part is not a chat box. It is the workbench around the model: retrieved context, specialist ownership, phase status, approval gates, execution records, and a clear handoff to a human owner.
If it can't be reviewed, it doesn't ship.
Every write-class AI operation we build carries an identity, an approval path, and an audit record. Those controls are part of the product design and release criteria from the start.
Bring an AI workflow and the decision it supports.
We define success criteria, evaluation data, approval boundaries, and operating controls before selecting the model architecture.